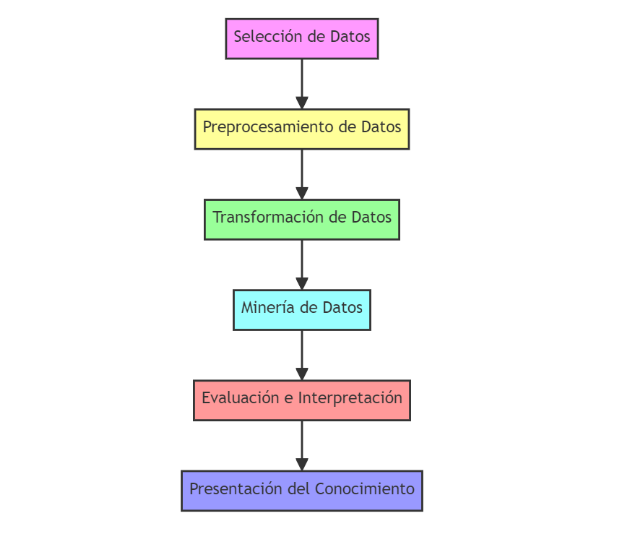
Proceso de descubrimiento de la información
El proceso de KDD (Knowledge Discovery in Databases), o Descubrimiento de Conocimiento en Bases de Datos, es una metodología utilizada para descubrir patrones y conocimiento útil a partir de grandes volúmenes de datos. Es un proceso completo que involucra varias etapas, desde la recopilación de datos hasta la interpretación final de los resultados. Consiste de las siguientes etapas:
1. Selección de Datos
En esta etapa, se seleccionan los datos relevantes para el análisis a partir de una base de datos. Se deben identificar y recopilar datos que sean pertinentes para el problema específico que se desea resolver.
2. Preprocesamiento de Datos
Una vez seleccionados, los datos suelen estar “sucios” o incompletos. En el preprocesamiento, se limpian, eliminan duplicados, se manejan valores faltantes y se normalizan para asegurarse de que estén en un formato adecuado para el análisis.
3. Transformación de Datos
Aquí, los datos se transforman y consolidan en formatos adecuados para el análisis. Esto puede incluir la reducción de dimensionalidad, la selección de variables, o la creación de nuevas variables derivadas. El objetivo es preparar los datos de manera que sean aptos para la aplicación de algoritmos de minería de datos.
4. Minería de Datos
Esta es la etapa central del proceso. En la minería de datos, se aplican técnicas y algoritmos para extraer patrones, modelos, o relaciones interesantes a partir de los datos. Esto puede incluir técnicas como clasificación, regresión, clustering (agrupamiento), reglas de asociación, entre otras.
5. Evaluación e Interpretación
Los patrones o modelos descubiertos se evalúan para determinar su utilidad y relevancia. Aquí se valida si los resultados obtenidos son consistentes y útiles para los objetivos establecidos al inicio del proceso. También se interpreta el significado de estos resultados en el contexto del problema.
6. Presentación del Conocimiento
Finalmente, el conocimiento descubierto se presenta de manera comprensible y utilizable para la toma de decisiones. Esta presentación puede ser a través de informes, visualizaciones, o sistemas de soporte a la decisión que ayuden a los tomadores de decisiones a aplicar los hallazgos en el contexto real.
Diagrama de flujo del proceso
Vista Minable
1. Concepto de “Vista Minable”
Una Vista Minable es una proyección específica de datos en un almacén de datos (data warehouse) que está diseñada y optimizada para ser utilizada en procesos de minería de datos. Su objetivo principal es estructurar los datos de manera que faciliten la identificación de patrones, tendencias y relaciones significativas. Las vistas minables se crean a partir de una o varias tablas del almacén de datos y usualmente se enfocan en un subconjunto de los datos relevantes para un análisis particular. Estas vistas permiten reducir la cantidad de datos a procesar y mejorar la eficiencia de los algoritmos de minería.
2. Vista Minable Diseñada
A partir de las tablas que tengo en mi almacén de datos, puedo diseñar una vista minable que relacione información sobre museos y visitantes. Esta vista me permitirá analizar la relación entre el número de visitantes y el tipo de museo o estado donde se encuentran los museos.
- Tablas involucradas:
- Museos (Información general de los museos)
- Visitantes (Registros de visitantes por museo)
- Estado (Ubicación geográfica de los museos)
- Atributos seleccionados para la vista minable:
- Nombre del museo (de la tabla Museos)
- Estado (de la tabla Estado)
- Total de visitantes (de la tabla Visitantes)
- Tipo de museo (de la tabla Museos)
- Año (de la tabla Visitantes)
La vista resultante podría verse como una combinación de estas tablas, ofreciendo un resumen de los museos y su cantidad de visitantes por estado y tipo.
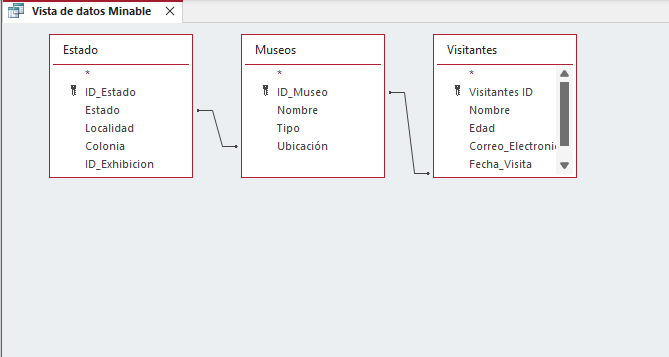
Imagen 1. Vista de diseño de la consulta
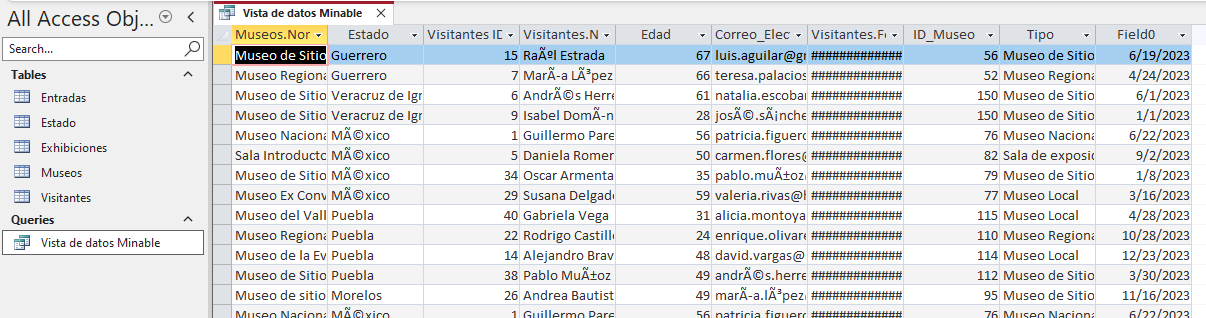
Imagen 2. Vista de tabla de la consulta
3. Formas de Explotación de la Vista Minable
- Análisis de Tendencias de Visitantes por Tipo de Museo: Utilizando esta vista minable, se puede analizar cómo ha cambiado la afluencia de visitantes a los diferentes tipos de museos a lo largo de los años. Por ejemplo, podríamos descubrir si los museos de historia natural han ganado popularidad en los últimos años o si los museos de arte han perdido visitantes.
- Comparación Geográfica de Visitantes por Estado: Esta vista también permitiría realizar un análisis geográfico de la distribución de visitantes. Podríamos detectar si ciertos estados o regiones reciben más visitantes en sus museos, lo que ayudaría a los gobiernos locales a tomar decisiones sobre inversión en infraestructura cultural. Además, podría servir para detectar estados con bajo flujo de visitantes y diseñar estrategias para mejorar la atracción turística en esos lugares.
Herramientas de minería de datos
1. Proceso de instalación de Orange
- Descargar orange
Imagen 1. Descarga de Orange
- Instalar orange
Imagen 2. Instalación de Orange
2. Visualización de la vista minable y demás pasos realizados
- Agregar Archivo CSV
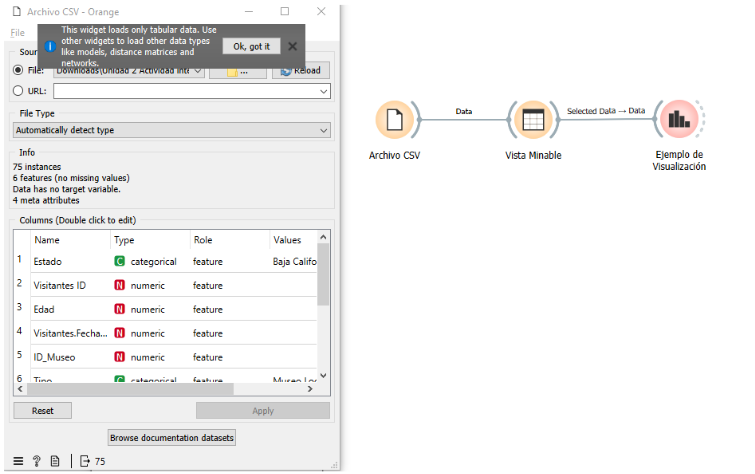
Imagen 3. Agregar archivo CSV
- Generar tabla de vista minable
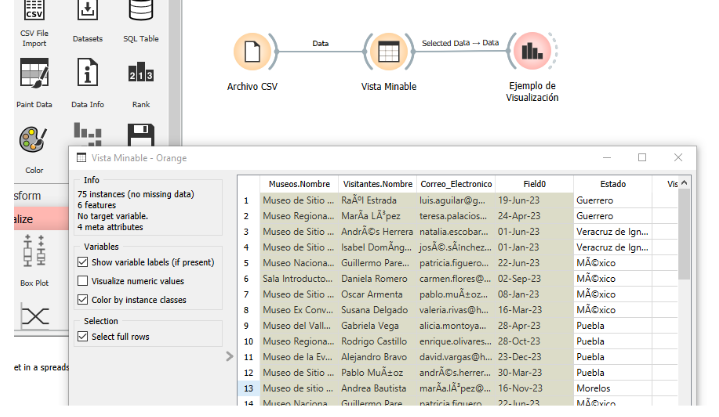
Imagen 4. Generar tabla de vista minable
- Generar una gráfica de visualización
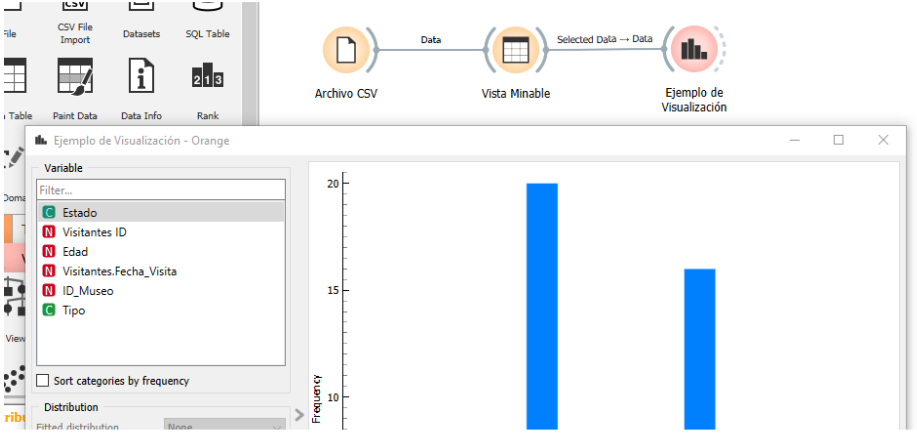
Imagen 5. Generar ejemplo de visualización
Procedimiento para obtener valores estadísticos básicos y visualizar datos en Orange
1. Cargar el conjunto de datos
- Abrí Orange e inicié un nuevo proyecto.
- Utilicé el widget File para cargar el conjunto de datos desde un archivo CSV. Para ello, arrastré el widget File al área de trabajo.
- Hice doble clic en el widget File y seleccioné el archivo deseado. Una vez cargado, los datos estaban disponibles para ser manipulados y analizados.
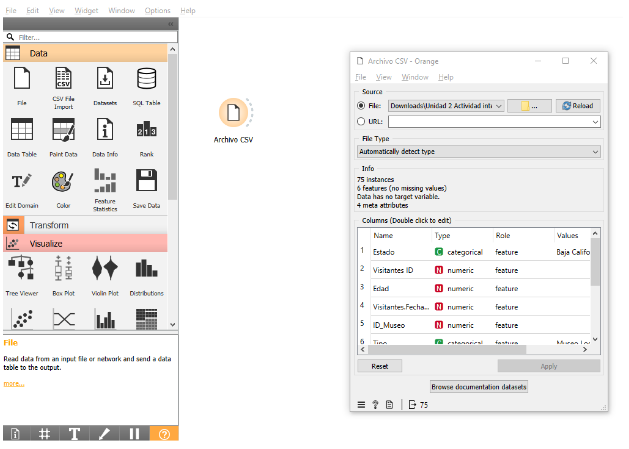
Imagen 1. Cargar el conjunto de datos
2. Explorar el conjunto de datos
- Para verificar los datos cargados, añadí el widget Data Table y lo conecté al widget File.
- Hice doble clic en el widget Data Table para abrir la tabla y explorar los datos, identificando los campos numéricos y asegurándome de que estaban correctamente cargados.
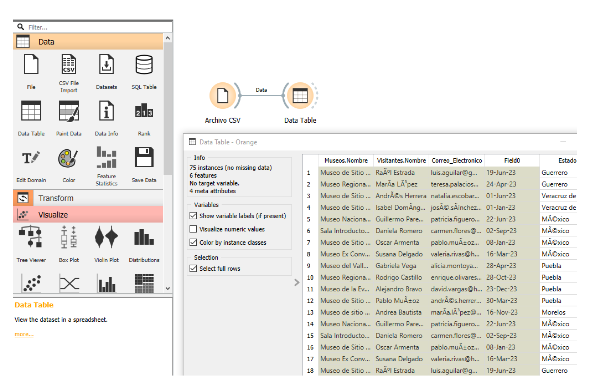
Imagen 2. Explorar el conjunto de datos
3. Calcular valores estadísticos básicos
- Para obtener los valores estadísticos del campo numérico de interés, añadí el widget Feature Statistics y lo conecté al widget Data Table.
- El widget calculó automáticamente los siguientes valores estadísticos:
- Distribución
- Media (Mean)
- Moda (Mode)
- Mediana (Median)
- Dispersión
- Mínimo (Min)
- Máximo (Max)
- Estos valores se presentaron de manera clara en el panel del widget.
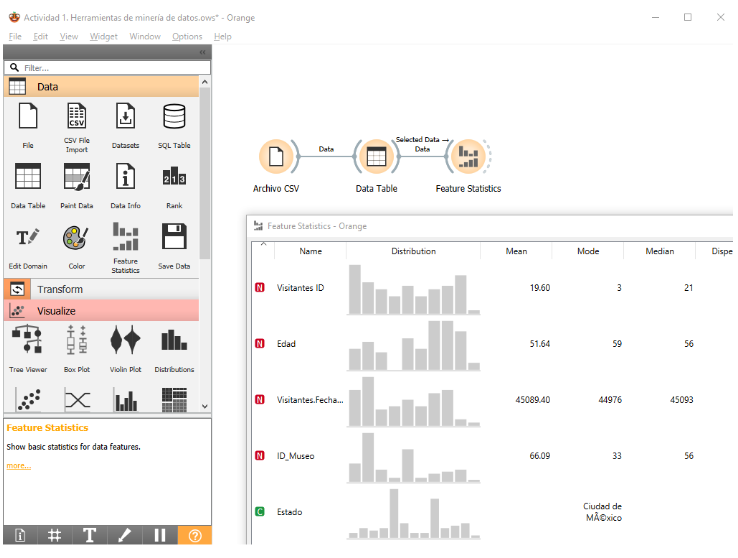
Imagen 3. Calcular valores estadísticos básicos
4. Visualización de la dispersión de datos
- Para obtener una visualización gráfica de los datos, añadí el widget Scatter Plot al área de trabajo y lo conecté al flujo de datos.
- Configuré el widget para visualizar la relación entre la variable edad y otra variable relevante del conjunto de datos.
- Personalize los colores del gráfico de dispersión para mejorar la visualización y facilitar la interpretación de los datos.
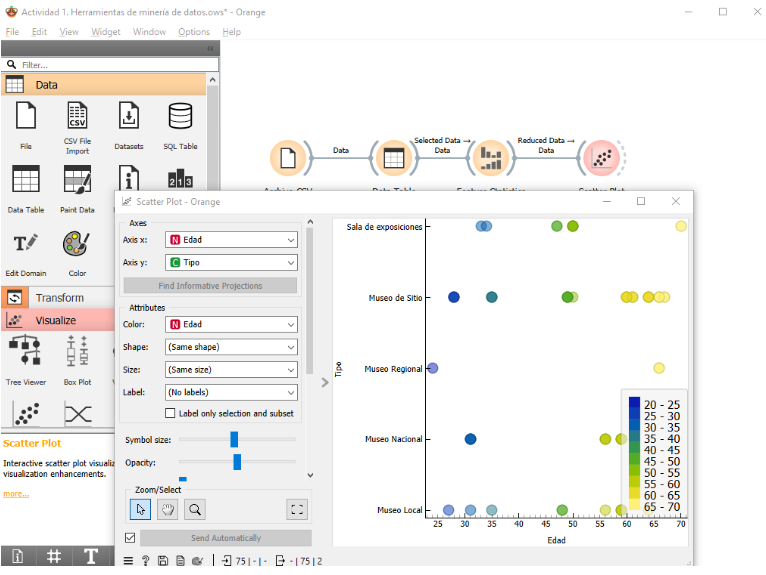
Imagen 4. Visualización de la dispersión de datos
Implementación de Tareas de Minería de Datos en Orange: Categorización y Predicción
Para esta actividad decidí explorar dos tareas de minería de datos utilizando Orange: categorización y predicción. Para esta actividad, trabajé con un conjunto de datos sobre visitantes de museos en diferentes estados de México, el cual incluye atributos como la edad de los visitantes, el tipo de museo visitado y las fechas de visita. Estas tareas permitirán categorizar a los visitantes y predecir posibles patrones de visitas.
1. Tarea de Categorización
- Carga del Conjunto de Datos:
- Abrí Orange y utilicé el widget File para cargar el conjunto de datos proporcionado.
- Verifiqué que los atributos como “Edad”, “Estado”, y “Tipo de Museo” estén correctamente definidos.
- Preprocesamiento de Datos:
- Filtré los atributos necesarios usando el widget Select Columns, seleccionando las variables “Edad” y “Tipo de Museo” para definir las categorías de visitantes.
- Apliqué normalización de datos estándar para mejorar la categorización.
- Aplicación del Método de Categorización:
- Usé el widget K-Means para clasificar a los visitantes en diferentes grupos
- Configuré el número de clusters para agrupar visitantes de acuerdo a características de edad o tipo de museo.
- Visualización de Resultados:
- Conecté el widget Scatter Plot para visualizar la agrupación de visitantes. Representé las variables “Edad” y “Tipo de Museo” en los ejes para observar patrones de agrupación.
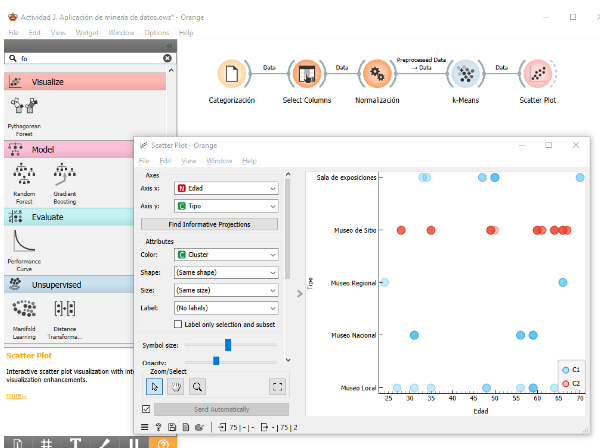
Imagen 1. Categorización de datos
2. Tarea de Predicción
La predicción se centrará en anticipar el rango de edad probable de los visitantes en función del tipo de museo y la frecuencia de visitas.
- Preparación del Conjunto de Datos:
- Utiliza el widget File para cargar el conjunto de datos, asegurándote de que las variables como “Edad” y “Tipo de Museo” estén configuradas correctamente.
- Define “Edad” como la variable objetivo para la predicción.
- División del Conjunto de Datos:
- Con el widget Data Sampler, divide los datos en conjuntos de entrenamiento y prueba, asignando el 70% para el entrenamiento y el 30% para la prueba.
- Selección del Modelo de Predicción:
- Emplea el widget Random Forest para predecir el rango de edad de los visitantes. Este modelo es adecuado para identificar patrones complejos en datos demográficos y categóricos.
- Evaluación del Modelo:
- Conecta los datos de prueba al widget Test & Score para medir la precisión del modelo utilizando métricas como el error cuadrático medio (RMSE) o el coeficiente de determinación (R²).
- Visualización de Resultados:
- Conecté el widget Scatter Plot para visualizar la distribución de los coeficientes generados
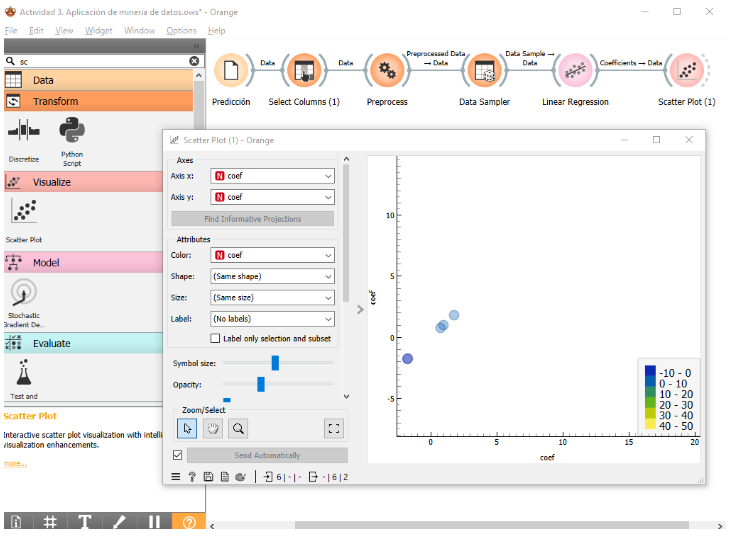
Imagen 2. Distribución de coeficientes
Análisis de Datos y Minería de Datos en Museos
1. Selección de Tarea de Minería de Datos
La vista minable contiene datos de visitantes y museos, lo cual me permite identificar patrones de visitas en función de la edad, tipo de museo, y ubicación. La tarea de minería de datos que considero relevante para esta vista sería el Análisis de Agrupamiento (Clustering). Implementar agrupamiento nos permitirá identificar segmentos de visitantes que comparten características similares, como la edad y el tipo de museo que prefieren.
Objetivo
El objetivo es descubrir patrones en el comportamiento de los visitantes en distintos museos, lo que puede ayudar a los administradores de museos a enfocar mejor sus esfuerzos de marketing y a personalizar la experiencia del visitante.
Implementación en Orange
- Cargar Datos: Importar los datos a Orange desde un archivo CSV para preprocesamiento.
- Preprocesamiento: Seleccionar características relevantes (Edad, Tipo de Museo, Estado).
- Clustering: Utilizar el widget de Clustering K-means para clasificar a los visitantes en grupos con características similares.
- Análisis de Resultados: Visualizar los resultados mediante un gráfico de dispersión para interpretar los segmentos y extraer conclusiones sobre las preferencias de los visitantes.
2. Tableros de Control para Seguimiento
Estado de actividades
Actividad | Estado | Fecha de Inicio | Fecha de Finalización | Notas |
Carga de Datos | Completado | 11/11/2024 | 11/13/2024 | Importar datos CSV en Orange |
Preprocesamiento de Datos | Completado | 11/11/2024 | 11/13/2024 | Seleccionar y limpiar características |
Implementación de Algoritmo de Clustering | Completado | 11/11/2024 | 11/13/2024 | Configurar y ajustar el algoritmo K-means |
Visualización de Resultados | Completado | 11/11/2024 | 11/13/2024 | Generar gráficos de dispersión y análisis visual |
Documentación del Proceso | Completado | 11/11/2024 | 11/13/2024 | Documentar resultados y conclusiones |
Métricas de Análisis
Métrica | Descripción | Valor Actual |
Número de Clústeres | Cantidad de clústeres creados en el análisis de clustering | 5 |
Distribución de Visitantes por Clúster | Cantidad de visitantes en cada clúster |
|
Preferencias de los Grupos (Tipo de Museo, Edad) | Descripción del tipo de museo y edad promedio por grupo |
|
3. Resultados Obtenidos y Visualización
Luego de realizar el análisis de clustering, se encontró que:
- Agrupación por Edad: La mayoría de los visitantes de museos de sitio pertenecen a un rango de edad mayor, mientras que las exposiciones atraen a visitantes más jóvenes.
- Preferencias geográficas: Los visitantes de ciertos estados prefieren tipos específicos de museos, posiblemente influenciados por el patrimonio cultural local.
- Patrones de Visita: Los visitantes mayores suelen visitar más frecuentemente los museos regionales y de sitio, mientras que los visitantes más jóvenes tienen preferencias más variadas.
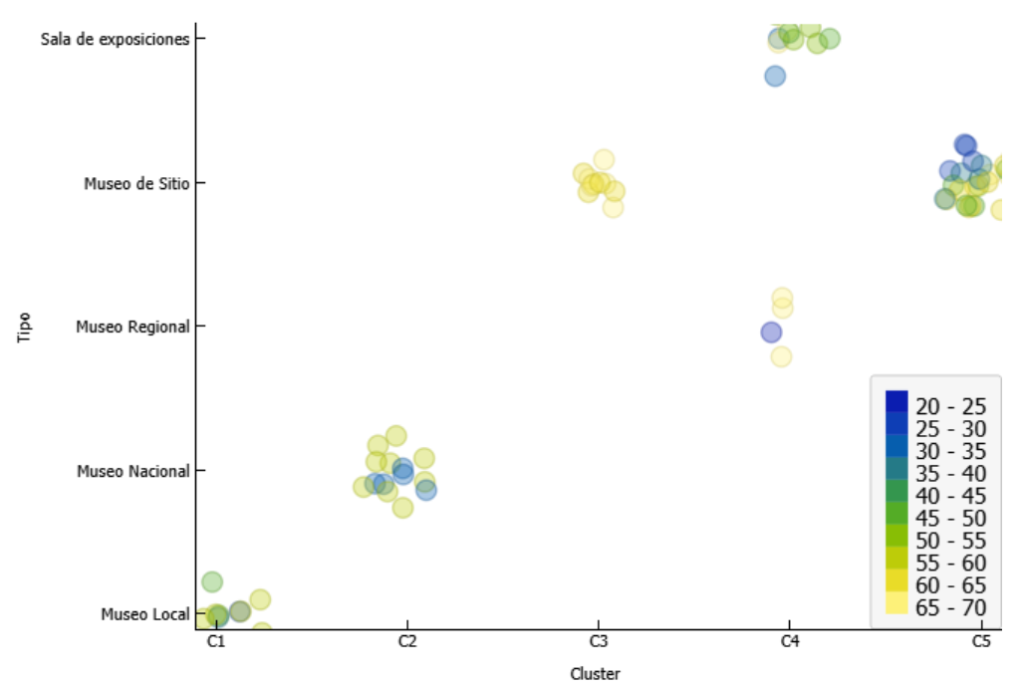
Imagen 1. Representación gráfica del clustering de los datos

Imagen 2. Análisis de la mediana de edad de visitantes por cluster
4. Conclusión
La técnica de clustering aplicada a los datos de visitantes en museos ha revelado patrones importantes de segmentación. Estos patrones pueden guiar futuras estrategias de promoción y mejora de servicios. Este enfoque basado en datos proporciona a los administradores de museos una herramienta efectiva para comprender mejor a sus visitantes y maximizar el impacto de sus esfuerzos en función de las preferencias y características de sus audiencias.